read more
Notes from lecture in COMP 411
PC is made of around 8 circuit boards
Each circuit board is made up of integrated circuits (8-16)
Each integrated circuit is made up of a module (8-16)
Each module is made up of cells (1,000-10,000)
Each cell is made up of gates (2-8)
Each gate is made up of transistors.
Notes about C
Basic pointers
———
To initialize a pointer variable (which is just going to hold a memory address of another variable), we do “ int *ptr; “ This should be initialized as null.
Say we have an int k, and we want to change ptr’s value to be the memory address of k. We would write the line “ptr = &k”.
Lastly, we can “dereference” a pointer, that is, retrieve the value stored at the location its pointing to by writing “ *ptr ”. We can also use this to change that value by saying “ *ptr = 7 “.
———
Array Pointers
———
When initializing an array, the compiler will store the entire array in a clump of (contiguous in) memory.
Also note that if we incremented the value of an integer pointer, ptr, such as with ptr++, then ptr’s value would actually rise by 4 (in a 32 bit machine, because the next four addresses in memory would have been reserved for the rest of that int). Note that if we were to do *ptr++, then the value that ptr was pointing to would increment by one.
Putting the above two together, we can see that if we initialize a pointer int *ptr; and an array int array[]={3,23,534,-4}; then we were to say ptr=&array[0]; then we’d have ptr pointing to the start of the array, and if we did a *ptr, we would get the value 3. If we did a ptr++, and then a *ptr, we would get a 23.
———
Structures
———
A structure is essentially a loose grouping of related variables, sort of like a class. In order to set aside memory/initiate some structure you can do a few things. You could say struct {…} x, y, z; which initiates the structure three times with these variables. Could also be done by saying struct var = {20, 50} where those values are assigned to the two “members” in the structure. You could also leave out that equals to just initiate the structure without setting values to the members. Can have nested structures. A structure can have arguments, such as struct point makepoint(int x, int y) {}. You can then create a point in this that assigns the arguments as the x and y of the created point. You can pass structures as the argument, such as by saying struct addpoint(struct point p1, struct point p2){}. It’s more efficient to pass pointers rather than the entire structure, so we should do that. In order to make an array of objects pretty easily, all you have to do is specify the object and then after the closing peace you put arrayName[size]; and then it’ll initialize memory for you. You can instantiate the objects in this array inline.
The dominant technology for integrated circuits is called CMOS (complemen tary metal oxide semiconductor). For CMOS, the primary source of power dissi pation is socalled dynamic power—that is, power that is consumed during switching. The dynamic power dissipation depends on the capacitive loading of each transistor, the voltage applied, and the frequency that the transistor is switched.
The reason we don’t have more registers necessarily is because having a lot would potentially slow down the computer because more/longer clocks might be needed.
Floating-Point.
A float with 64 bits of precision (twice the standard 32), is called a “double”.
This is a 32 bit number. There’s a bit for sign. 8 bits for the exponent that 2 is raised to. And the remaining bits are used for what number you’re actually raising it to. A one is assumed to be there (don’t really get this part). Using two as the base of the exponent is good because it just means you have to shift the significand up and down.
With S being the sign bit, F being the actual digits of the number, E being the exponent.
Zero in floating point is just the smallest positive number possible that can be created. There is a negative and positive 0.
Also uses E=255 to represent numbers that are exceptions, that is NAN (not a number).
Positive infinity is the largest number that can be created with floating point while negative infinity is the opposite.
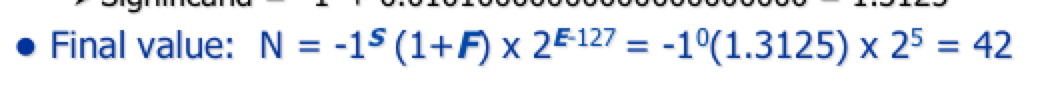 

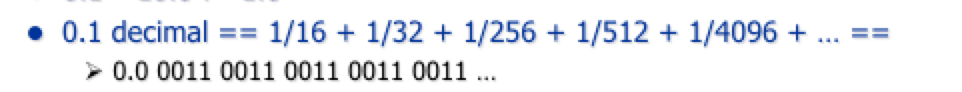 
Gate stuff:
A multiplexer is essentially a controller. It has at least three inputs, one as the controlling input that decides whether to “copy” one input or the other to the output. Essentially, it could determine whether the inputs go through one process or another. Think of multiplexers as switches.
ROMs are Hardwired memory!
Latches are used for faster memory, you can create a feedback loop on a multiplexer to allow the storing and reading of states. Maintains state as long as power is applied. Requires more power.
Having two latches in sequence counters propagation delays. My question is why is the input flipping almost randomly/too fast for transistors to process? Like aren’t you missing stuff?
First time seeing the clock come in! So the clock will alternate really quickly between 0 and 1, and it’s connected to all of these little components and it’s in charge making these states move. So for instance on the first of these two latches in sequence, you could have a clock high input as the controller for one and a clock low input controller as the other. This would ensure that not both would be open at the same time. As the clock alternates, things actually move (charges transfer) in the circuit. You can overclock because these circuits are build to leave a little bit of delay just so that an error pretty much never happens. When you over clock, you run the risk of bleeding inputs through certain gates because the clock speed you normally run at was chosen so that almost 100% of the time, all of the flip flop gates and everything else controlled by the clock had time to settle down before the next phase happened. Essentially, you would set the clock to whatever the slowest operation took plus a little extra just in case. You can play with that just in case part (over clocking), but if you go too far, you will bleed.
SRAM: Static RAM, which is for the cache. This is where the charge is stored between transistors. It’s the flip flop solution, and it requires a lot more space and is thus much more expensive than DRAM but it’s faster. Doesn’t require refreshing?
DRAM: Dynamic RAM, is slower but much less expensive. This is the RAM that you’ll most likely refer to. It consists of arrays of capacitors that are read and written. Note upon reading, one must recharge that cell because that effectively destroys the charge. This makes it slower.
http://computer.howstuffworks.com/ram3.htm
You can use SRAM to keep track of states so that you can do basic evolutions with a clock as the controller essentially. You have combinational logic that’s fed with an input (which could be just the state (part of or entirety of last output)) or state and other input. So the latches sort of act as temporary memory (a state), and that gets fed in to the combinational logic possibly with other input at a clock rate (determined by the clock, obviously) and then each of those outputs gets used somewhere to do something as well as gets fed in for the next evolution.
CPU time is: The actual time the CPU spends computing for a specific task. This can also be split into user CPU time and system CPU time (how much the CPU is dealing with the operating system for that task).
The vocabulary of a CPU is the “instruction set”. What vocabulary that might be is dependent on the instruction set architecture.
A linker is the last stage in the compilation process. First comes the compiler that brings the code to assembly language, and then the assembler that brings it almost to machine code with the exception of a few more links that need to be done by the linker: A systems program that combines independently assembled machine language programs and resolves all undefined labels into an executable file.
A data “bus” is just a signal wider than 1 bit. So you may have a 32-bit bus to connect the CPU to the memory or something.


Gate stuff:
A multiplexer is essentially a controller. It has at least three inputs, one as the controlling input that decides whether to “copy” one input or the other to the output. Essentially, it could determine whether the inputs go through one process or another. Think of multiplexers as switches.
ROMs are Hardwired memory!
Latches are used for faster memory, you can create a feedback loop on a multiplexer to allow the storing and reading of states. Maintains state as long as power is applied. Requires more power.
Having two latches in sequence counters propagation delays. My question is why is the input flipping almost randomly/too fast for transistors to process? Like aren’t you missing stuff?
First time seeing the clock come in! So the clock will alternate really quickly between 0 and 1, and it’s connected to all of these little components and it’s in charge making these states move. So for instance on the first of these two latches in sequence, you could have a clock high input as the controller for one and a clock low input controller as the other. This would ensure that not both would be open at the same time. As the clock alternates, things actually move (charges transfer) in the circuit. You can overclock because these circuits are build to leave a little bit of delay just so that an error pretty much never happens. When you over clock, you run the risk of bleeding inputs through certain gates because the clock speed you normally run at was chosen so that almost 100% of the time, all of the flip flop gates and everything else controlled by the clock had time to settle down before the next phase happened. Essentially, you would set the clock to whatever the slowest operation took plus a little extra just in case. You can play with that just in case part (over clocking), but if you go too far, you will bleed.
SRAM: Static RAM, which is for the cache. This is where the charge is stored between transistors. It’s the flip flop solution, and it requires a lot more space and is thus much more expensive than DRAM but it’s faster. Doesn’t require refreshing?
DRAM: Dynamic RAM, is slower but much less expensive. This is the RAM that you’ll most likely refer to. It consists of arrays of capacitors that are read and written. Note upon reading, one must recharge that cell because that effectively destroys the charge. This makes it slower.
http://computer.howstuffworks.com/ram3.htm
You can use SRAM to keep track of states so that you can do basic evolutions with a clock as the controller essentially. You have combinational logic that’s fed with an input (which could be just the state (part of or entirety of last output)) or state and other input. So the latches sort of act as temporary memory (a state), and that gets fed in to the combinational logic possibly with other input at a clock rate (determined by the clock, obviously) and then each of those outputs gets used somewhere to do something as well as gets fed in for the next evolution.
CPU time is: The actual time the CPU spends computing for a specific task. This can also be split into user CPU time and system CPU time (how much the CPU is dealing with the operating system for that task).
The vocabulary of a CPU is the “instruction set”. What vocabulary that might be is dependent on the instruction set architecture.
A linker is the last stage in the compilation process. First comes the compiler that brings the code to assembly language, and then the assembler that brings it almost to machine code with the exception of a few more links that need to be done by the linker: A systems program that combines independently assembled machine language programs and resolves all undefined labels into an executable file.
A data “bus” is just a signal wider than 1 bit. So you may have a 32-bit bus to connect the CPU to the memory or something.
 What is #pragma? It’s a directive that’s used in C to tell the compiler extra stuff.
For cache stuff, the tag is the memory address that you’re using there, and the data is the data that’s at that memory location. You can make the line size greater than 1 to store memory that’s in sequence (this may be helpful for array traversing). Apparently 32 bytes per line is common, so that’s 8 words per tag (so every time you do a lookup, you can get that item and 7 after it).
Because adding anything in memory to the cache is fair game, you essentially do “memory address mod cache size” to figure out how to do a mapping. That is, you’ll have certain memory locations mapping to the same cache location.
How caching works (direct mapped, which is cheaper but slower): So everything gets broken down by some specifications of the cache, and these are (tag bit size, index bit size, offset bit size, and byte-addressed/word-addressed). You’re being fed with memory addresses and obviously you’re not going to be able to store all of what’s in main memory into the cache so you need a way of translating those main memory addresses into cache memory addresses. So the way that’s done is you split up the main memory address into three sections, the tag, the index, and the offset (these are three numbers listed in the cache specification). The index field is used to figure out which index in the cache a given byte of memory should go, ignoring the tag field and the offset (which essentially is taking the entire memory address mod
What is #pragma? It’s a directive that’s used in C to tell the compiler extra stuff.
For cache stuff, the tag is the memory address that you’re using there, and the data is the data that’s at that memory location. You can make the line size greater than 1 to store memory that’s in sequence (this may be helpful for array traversing). Apparently 32 bytes per line is common, so that’s 8 words per tag (so every time you do a lookup, you can get that item and 7 after it).
Because adding anything in memory to the cache is fair game, you essentially do “memory address mod cache size” to figure out how to do a mapping. That is, you’ll have certain memory locations mapping to the same cache location.
How caching works (direct mapped, which is cheaper but slower): So everything gets broken down by some specifications of the cache, and these are (tag bit size, index bit size, offset bit size, and byte-addressed/word-addressed). You’re being fed with memory addresses and obviously you’re not going to be able to store all of what’s in main memory into the cache so you need a way of translating those main memory addresses into cache memory addresses. So the way that’s done is you split up the main memory address into three sections, the tag, the index, and the offset (these are three numbers listed in the cache specification). The index field is used to figure out which index in the cache a given byte of memory should go, ignoring the tag field and the offset (which essentially is taking the entire memory address mod (2index bit size)-offset to figure out which index to store it in). This also implies that a cache will have 2(index bit size) of entries in it. Now, because of memory use is often associated with locality, for each index we store more than just 1 byte/word, in fact we store 2(offset bit size) bytes/words. Whether a byte or a word is stored in each of these offsets is determined by the cache specification (byte-addressing/word-adressing). This way if we had a miss in the cache and had to fetch a byte/word, and then the next clock we needed the byte/word right after that one (very likely for array traversal), we would already have that byte/word because we picked up the next 2(offset bit size) after it. Now, obviously we need a way to figure out which of the ((main memory address max) mod (#of cache indices)) possible lines could be stored at any given cache index, so at each index in the cache we store the tag associated with what line is currently being stored at that index. That way you can tell if you have a hit in memory by looking at the appropriate index in the cache and then checking to make sure that the tag is correct.
Understand fully associative (faster but much more expensive): seems like you can put any value in any slot. When determining if you already have an address stored in the class, you can simultaneously do an XNOR on every tag in the cache to see if it’s stored. If you get a hit, check to see if that slot’s “valid” bit is 1 (must be 1 for a hit). You still have offset to keep track of what part of a cache line the value is actually stored.